


あくまで備忘録なんで雑に記録します最初にitemgetter
区間スケジューリングに、「リスト in リスト」の後ろ側の要素でソートする必要があるので
from operator import itemgetter
A = [[1, 2], [5, 3], [10, 1]]
A = sorted(A, key=itemgetter(1))
print(A)
#[[10, 1], [1, 2], [5, 3]]
#もしくは key=lambda x:x[1]区間スケジューリング問題①
終点でソートされたリスト in リスト([始点, 終点], [始点, 終点][始点, 終点])を全まわし
①最小の終点を取り除き
②それより前の始点はパス
③次に最小の終点〜



from operator import itemgetter
n = int(input())
A = [list(map(int, input().split())) for _ in range(n)]
A = sorted(A, key=itemgetter(1))#まずitemgetter(1)で終点でソート
removed = -1#取り除いていく
count = 0
for startpoint, endpoint in A:#Aは(始点、終点)のリストインリスト
if removed < startpoint:
removed = endpoint
count += 1
print(count)
区間スケジューリング問題②串刺しのイメージ
わかりやすいイメージで書いてくれている

from operator import itemgetter
m, n = map(int,input().split())
A = [list(map(int, input().split())) for _ in range(n)]
A = sorted(A, key=itemgetter(1))#まずitemgetter(1)で終点でソート
removed = -1#取り除いていく
count = 0
for startpoint, endpoint in A:#Aは(始点、終点)のリストインリスト
if removed <= startpoint:
removed = endpoint
count += 1
print(count)
# 5 10
# 1 2
# 1 3
# 1 4
# 1 5
# 2 3
# 2 4
# 2 5
# 3 4
# 3 5
# 4 5
#4なぜ最小の終点をとっていけば、最多の区間を取れるのか考察
時間軸を右にとって、たくさんの(始点、終点)がある仕事があったとする
まず、時刻が1番速く終わる仕事(下図①)を考える

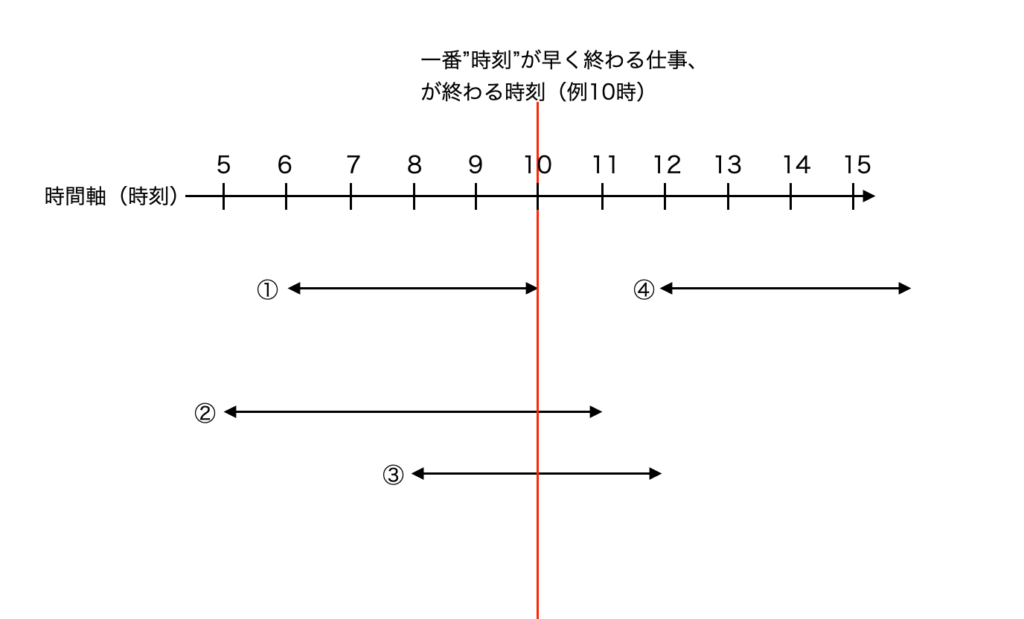
④の様に、後ろで重ならない仕事
のいずれか
10時の時点では、「完了仕事」の個数の最多は1(当然①を採用して)

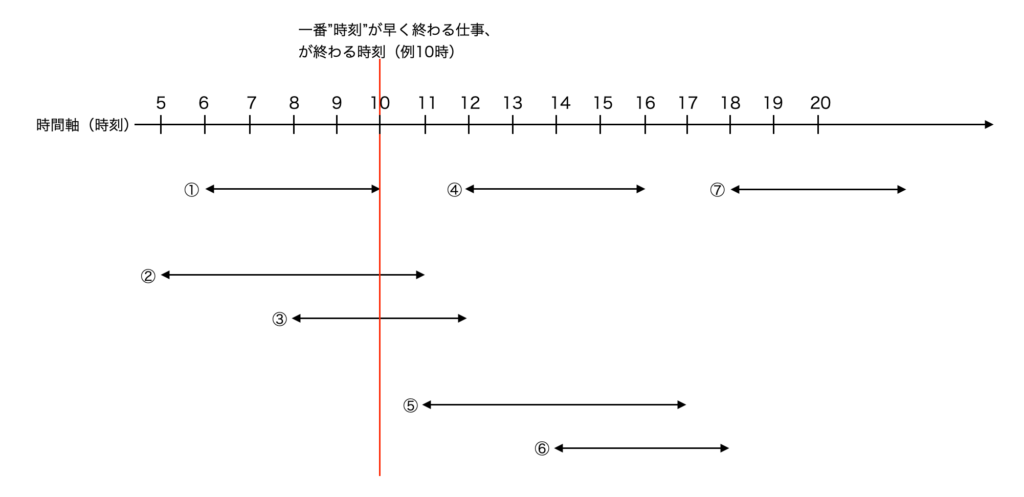
第1ステップ:まず最も早く終わる仕事①を選び、②③など、①に重なる仕事は省く
④⑤⑥⑦・・・など、①に重ならない全ての中で最も早く終わる仕事④を次に選ぶ
10時の時点で、終えれる仕事の最多の個数は”1”(それより前に終わる仕事はないから)
16時(④の終わる時間)未満では終えれる仕事の最多の個数は”1”
(理由1:①と重なっている仕事(②や③)は①と同時に仕事ができないし、①と重なっていて①より後に終わる以上、お互いも必ず重なる=10時を通る)
(理由2:⑤⑥⑦・・・などは、④より終わる時間が遅い)
16時(④の終わる時間)の時点で、終えれる仕事の最多の個数は”2”
帰納法
命題:ある期間で最多の仕事を終えるには、1.最も終わりの早い仕事を選択し、2.重なる仕事は排除し、3.残りの仕事から最も終わりの早い仕事を選択する、を繰り返す事になる
仮定:k個目の仕事を完了する終了時刻x時の時点で終えれる仕事の最大の個数を”k”として、
k個目の仕事を選択した場合、残りの仕事は次の2通り
ケース1:x時の時点で開始しているが終了していない(k個目の仕事と重なっている)仕事
ケース2:x時の時点で始まっていない(k個目の仕事と重なっていない)仕事
ケース1は”x時の時点で終了していない”という点で重なりあっているので、ケース1は全て排除(理由はこなせる個数が最大でも”k”個というk個目の仕事を上回る事は出来ないから)
残りのケース2から最も早い仕事を”k+1”個目の仕事とし、終了時刻をy時とする
[x〜y)時の間で行える最多の仕事はk個であるというのが、k=1〜nで成り立つ
ちょっと書き方が曖昧かもしれんですけど・・・


コメント