


あくまで備忘録なんで雑に記録しますスクレイピング
こすり落とす、削り取るの意味
Webサイトから文字通り、”情報をこそげ取る”のでしょう
例:GoogleのクローラーのGooglebotが、Webサイトを巡回して情報収集する
参考:スクレイピング・ハッキング・ラボ
スクレイピング・ハッキング・ラボ Pythonで自動化する未来型生活
参考:図解!Python BeautifulSoupの使い方を徹底解説!
図解!Python BeautifulSoupの使い方を徹底解説!(select、find、find_all、インストール、スクレイピングなど)
上の書籍を実際にやりながら、下のリンクやUdemyで理解を深める手順が一番よかったです
あるサイト内容が更新されたか目視は大変
それで、RSS(リッチサイトサマリー)フィードをRSSリーダーで読み取って新着確認をしていた
ところが、SNS全盛になってRSSの役割も衰退(提供する側もしたりしなかったり)
スマホやWebプッシュは不便も多い
それならスクレイピングが自由度が高くていいよね(著作権法・不正アクセス禁止法には注意)
Beautiful Soup・Requestsを使って、Wikipediaから「今日は何の日」を取得する
上澄みの美しいスープって感じかな?
Requests・・・情報を持ってくるにはhttp/https通信を行う必要あり
BeautifulSoup・・・HTMLを要素単位で解析
>>>import requests
>>>
>>>from bs4 import BeautifulSoup
>>>あった
(無かったら、ModuleNotFoundError: No module named 〜って出る)
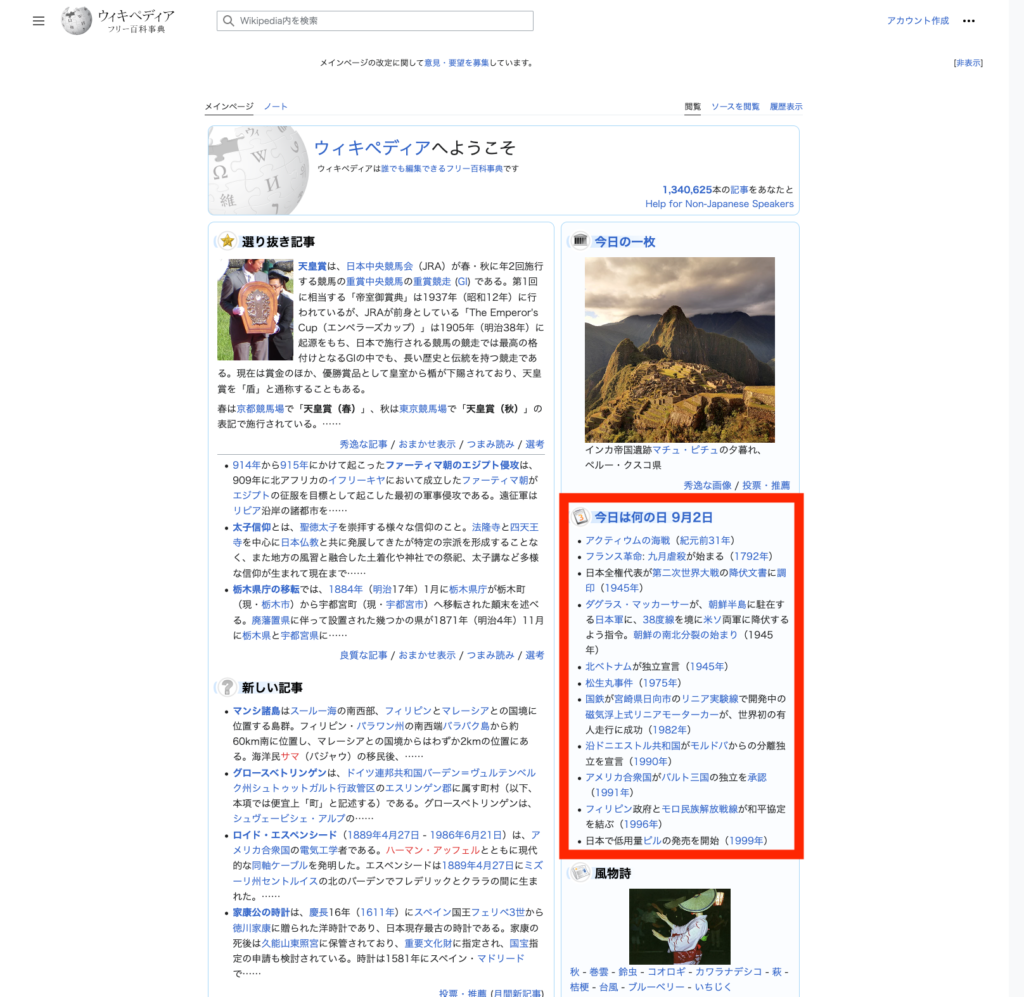
↓赤枠の部分を取り出します

>>>import requests
>>>from bs4 import BeautifulSoup
>>>url = "https://ja.wikipedia.org"
>>>res = requests.get(url)
>>>soup = BeautifulSoup(res.content, "html.parser")
>>>today = soup.find("div", attrs={"id": "on_this_day"})
>>>today_article = today.text
>>>print(today_article)
今日は何の日 9月2日
アクティウムの海戦(紀元前31年)
フランス革命: 九月虐殺が始まる(1792年)
日本全権代表が第二次世界大戦の降伏文書に調印(1945年)
ダグラス・マッカーサーが、朝鮮半島に駐在する日本軍に、38度線を境に米ソ両軍に降伏するよう指令。朝鮮の南北分裂の始まり(1945年)
北ベトナムが独立宣言(1945年)
松生丸事件(1975年)
国鉄が宮崎県日向市のリニア実験線で開発中の磁気浮上式リニアモーターカーが、世界初の有人走行に成功(1982年)
沿ドニエストル共和国がモルドバからの分離独立を宣言(1990年)
アメリカ合衆国がバルト三国の独立を承認(1991年)
フィリピン政府とモロ民族解放戦線が和平協定を結ぶ(1996年)
日本で低用量ピルの発売を開始(1999年)順番に
>>>url = "https://ja.wikipedia.org"①URLを変数として指定
>>>res = requests.get(url)②対象のURLに『HTTPリクエスト』を送り、レスポンスを取得(requestsライブラリの真骨頂)
ただこのままだと、htmlタグだらけのhtml全文を読み込んだだけ
>>>soup = BeautifulSoup(res.content, "html.parser")③読み込んだhtmlを、BeautifulSoupでタグ(divとか)単位に解析
・書き方:BeautifulSoup(解析対象のHTML/XML, 利用するパーサー)
・text=テキスト属性、content=バイナリ属性(参考:Python, Requestsの使い方)
・パーサー(解析器)の中でも、Python’s html.parserを指定
>>>today = soup.find("div", attrs={"id": "on_this_day"})④開発者ツールでWikipedia今日は何の日の、タグは<div>、IDはon_this_day、と調べる
BeautifulSoupのfind()メソッドでこの範囲のみ抽出
この部分は【備忘録】スクレイピング②BeautifulSoupの抽出へ
>>>today_article = today.text
>>>print(today_article)⑤textメソッドでテキストのみを抽出、そして出力


コメント